
Abstract
Numerous studies have shown that more visual features can be stored in visual short-term memory (VSTM) when they are encoded from fewer objects (Luck & Vogel, 1997, Nature, 390, 279–281; Olson & Jiang, 2002, Perception & Psychophysics, 64[7], 1055–1067). This finding has been consistent for simple objects with one surface and one boundary contour, but very few experiments have shown a clear performance benefit when features are organized as multipart objects versus spatially dispersed single-feature objects. Some researchers have suggested multipart object integration is not mandatory because of the potential ambiguity of the display (Balaban & Luria, 2015, Cortex, 26(5), 2093–2104; Luria & Vogel, 2014, Journal of Cognitive Neuroscience, 26[8], 1819–1828). For example, a white bar across the middle of a red circle could be interpreted as two objects, a white bar occluding a red circle, or as a single two-colored object. We explore whether an object benefit can be found by disambiguating the figure–ground organization of multipart objects using a luminance gradient and linear perspective to create the appearance of a unified surface. Also, we investigated memory for objects with a visual feature indicated by a hole, rather than an additional surface on the object. Results indicate the organization of multipart objects can influence VSTM performance, but the effect is driven by how the specific organization allows for use of global ensemble statistics of the memory array rather than a memory benefit for local object representations.
Similar content being viewed by others

A central question in research on visual short-term memory (VSTM) has been whether memory capacity is determined or influenced by the number of objects one attempts to remember across a brief retention interval as opposed to capacity being determined solely by the total amount of featural information in the display. Models of VSTM that emphasize discrete item limits, or slots (Rouder et al. 2008; Zhang & Luck, 2008), and models that characterize VSTM as a more flexible continuous resource (Bays, Catalao, & Husain, 2009; Wilken & Ma, 2004) have both been proposed. This debate is ongoing, but there is substantial evidence that something like an object limit plays a role in determining capacity limits (Awh, Barton, & Vogel, 2007; Cowan, 2001). Some models have suggested influence of both discrete and continuous resource limits to account for findings in support of both ideas (Sewell, Lilburn, & Smith, 2014).
Early studies by Allport (1971) and Wing and Allport (1972) found support for the idea that multiple features of different dimension (e.g., shape and color) from the same object could be remembered at no apparent performance cost, while features of the same dimension (e.g., two shapes) on one object could not. This finding is in line with the conceptualization of visual modularity suggested by Treisman (1969), Lappin (1967), and later research by Magnussen, Greenlee, and Thomas (1996), where independent feature analyzers process certain types of visual information somewhat independently of one another. However, studies by Duncan (1984, 1993) suggest that remembering different feature dimensions incurs a cost when they are located on different objects, supporting the idea that number of objects is also a limiting factor. Two features from independent dimensions (tilt, texture, size, and gap location) were more accurately reported when they were both located on one object versus being split between two objects (Duncan, 1984). This finding was later replicated using size and shape (Duncan, 1993). Additionally, Duncan (1993) and Duncan and Nimmo-Smith (1996) showed that when features from the same dimension were located on two separate objects, performance was no different from different dimension features located on two separate objects. Both types of dual feature discriminations incurred a memory performance cost.
Experiments by Luck and Vogel (1997) suggested object number was the only limit on VSTM capacity, even finding that participants could encode additional same dimension features (two colors) without performance cost as long as the number of objects remained the same. This critical experiment compared color memory performance between single-color objects and bicolor objects. However, studies attempting to replicate this finding for bicolor objects have been unsuccessful (Olson & Jiang, 2002; Wheeler & Treisman, 2002; Xu, 2002b). It would appear from these follow-up studies, and the work of Allport and colleagues, that there is indeed a performance cost to encoding multiple features of the same dimension on an object. Olson and Jiang (2002) presented this issue as a competition between three possibilities: the strong-object theory, multiple resources theory, and the weak-object theory. The strong-object theory is in line with the suggestion of Luck and Vogel (1997) that VSTM capacity is only limited by the number of objects, and that the number of features that constitute those objects is of no consequence to memory capacity. In this case, all features of an object are encoded and stored in parallel such that remembering multiple visual features from a single object (color, size, orientation, etc.) is as easy as remembering one feature from a single object. The multiple resources theory suggests that the number of features is the limiting factor in VSTM. The main assertion of this theory is that VSTM consists of parallel limited resources for representing different feature types. For instance, storing more than one orientation or more than one color incurs a performance cost, but storing one color and one orientation does not incur a cost because they use separate resources. The weak-object theory suggests both feature number and object number play a part in limiting VSTM capacity in some way. In a series of experiments, Olson and Jiang (2002) were able to reject the strong-object theory by showing worse performance for bicolor objects compared with the same number of single-color objects. Also, the multiple resources theory was rejected because of the finding of better performance for color and orientation memory when both features were conjoined on colored rectangles rather than when presented on separate colored squares and oriented rectangles. It would seem both the number of features and objects affect VSTM capacity limit in some way.
From the evidence outlined above it is tempting to conclude that there is a feature limit, as described by the multiple resources theory, but also a separate cost to encoding and remembering spatially distinct objects. If this is true, bicolor objects are remembered more poorly than single-color objects because the color representation resource is divided between two targets on each object. However, it is not entirely clear that the observed performance cost is due to the features being of the same dimension or the fact that the features must occupy distinct spatial locations, a problem not inherent to objects with features of different dimensions. Color and orientation can be inherent to the same object surface, while two colors must abut in some way and create two distinct surfaces. It is possible that the parallel representation of different dimension features from the same object observed by Duncan (1984, 1993), Luck and Vogel (1997), and others is due to the features being inherent to the same object surface. Object representations may be unable to integrate abutting features that are inherent to different surfaces as a single unit, regardless of whether they are the same or different dimensions. Until this possibility is excluded, the limitation on VSTM could be more related to the number of surfaces that can be remembered rather than the number of objects.
Multipart objects
Xu (2002a, 2002b, 2006) examined this possibility extensively in a series of experiments examining change-detection performance for objects with two task-relevant features, whose features were indicated by different parts of the object (see Xu, 2002a, Fig. 3). For instance, one type of object configuration that was tested featured a colored circle with a black bar across the front of it to indicate orientation. In this case, the orientation feature and the color feature were from different surfaces. In Xu (2002a), conjunction conditions like this were compared with disjunction conditions in which the black orientation bars and colored circles were separated in space. One novel aspect of the Xu’s analysis of results in this study was comparing the relative performance cost when both feature types of each object were required to be remembered with trials where only one feature type from each object was required to be remembered. In other words, for each conjunction and disjunction condition, there were trials where participants were told to monitor only one of the two feature types, and trials where participants were asked to monitor both feature types. Within each condition, Xu took the difference in performance between the trials where only one feature type was monitored and the trials where both feature types were monitored. This value was then compared between conjunction and disjunction display conditions to determine which stimulus type had the greatest performance cost for monitoring an additional feature type.
A possible issue with this metric is this type of object benefit does not necessitate an overall better change-detection performance for multipart objects compared with single-feature objects. In many of Xu’s experiments, performance was equivalent for conjunction and disjunction displays when monitoring both feature types, but an object benefit was still claimed because of poorer performance for the conjunction displays when only one feature type was task relevant (see Xu, 2002a, Fig. 7). Xu argued that it is more difficult to extract individual features from a complex multipart object, causing the performance disparity in the single-feature-type conditions. However, even if monitoring an individual feature is more difficult when it is part of a multipart object, it is not necessarily also more difficult when the task requires monitoring all feature types from the same object. Also, the performance benefits seen in previous research and in Experiments 2 and 3 of Xu (2002a) for simple, single-surface objects with two task-relevant features show a better absolute performance when compared with disjunction conditions where the features all appear on separate objects. At the very least, the same magnitude of effect is not occurring for multipart objects.
Only one display type in Xu (2002a) showed better absolute performance than a disjunction comparison condition when monitoring both feature types (using stimuli with colored circles and tails oriented left, center, or right). A separate study showed a similar benefit for mushroom-like objects where the color feature was in the cap and the orientation feature was indicated by the angle of the stem (Xu, 2002b). These mushroom objects were almost identical to the previously mentioned stimuli showing an object benefit. Contrary to the color-orientation findings, there was no performance benefit for conjunction displays when the mushroom objects were displayed with two colors (one color for the cap and a different color for the stem) instead of a color and an orientation. It would seem that, at least for different dimension features (i.e., color and orientation), it is possible to get a performance benefit even when features are indicated by different parts on an object.
The object benefit found for color-orientation conjunctions using mushroom objects was later replicated by Delvenne and Bruyer (2006), but it should be noted that while significant, the effect was attenuated after attempting to control for use of global spatial layout in the displays. Delvenne and Bruyer (2006) suggested that the way orientation was indicated by the tails/stems of the objects may have allowed participants to perform the orientation discrimination by remembering the relative spatial locations of the items in the array rather than the specific orientations of each stem. Orientation change detection could then be achieved by detecting the position change of the object tail toward or away from the other objects rather than remembering its specific characteristics. This factor is potentially confounding because there is evidence that the global spatial configuration of a display is processed preattentively and may be remembered better than object features (Aginsky & Tarr, 2000; Simons, 1996).
If encoding features from multipart objects is more efficient than encoding the same number of features from single-feature objects, then it is important to consider why all the conditions tested by Xu did not show the same pattern of results. Out of the stimuli tested by Xu (2002a, 2002b), the two types of multipart objects that did show a clear performance benefit over their disjunction controls were structurally very similar. Both configurations had a change in surface color at the same point as a negative minimum of curvature. Interestingly, in a later study, Xu (2006) reported an experiment in which she used objects structured as colored balls with a shape on their tail instead of an orientation. The results showed no performance advantage when participants were monitoring both feature types, contrary to the aforementioned color-orientation objects. It may be that these inconsistencies are due to the inability of participants to perform the shape memory task using the global spatial configuration of the display like Delvenne and Bruyer (2006) suggested was possible for the orientation judgment. Another possible reason why some stimuli did not show a performance benefit may be because in some cases, such as when a colored circle has an orientation bar going through it, one may consider this to be two things with one occluding the other in depth rather than representing a single unified object. Figure–ground organization is somewhat ambiguous in displays without depth cues or other indications of connectedness aside from local proximity.
A similar suggestion was made by Balaban and Luria (2015). They proposed the most basic object is a surface property, color or perhaps texture, and the boundary of its expanse. A configuration with more than one surface property may be perceived as two objects. Further, a stimulus with only one surface and boundary should be mandatorily processed as a unified object because that is the only possible interpretation of the figure, whereas a stimulus with more than one surface or boundary property is essentially the integration of multiple basic objects and is thereby “demanding, gradual, and nonobligatory” because it is not the only possible visual interpretation of the configuration (Balaban & Luria, 2015). Research by Luria and Vogel (2014) and Balaban and Luria (2015) examined how the Gestalt cue of common fate might disambiguate figures with two surface properties and contribute to their integration in VSTM.
Luria and Vogel (2014) concentrated their study on color–color conjunctions by comparing four conditions differing in the spatial positions and movement patterns of the memory stimuli during study: one condition with four separate colors, one with two separate colors, one with two bicolor objects, and one where four colors started separately but converged to the same location during the study phase of each trial. They also manipulated how long the objects remained stationary after the movement period. Their results suggest a possible behavioral benefit for the condition where four colors organized into bicolor objects when a common fate cue is present, but the effect appears to be inconsistent or possibly dependent on the length of the stationary period during the study phase (Luria & Vogel, 2014). Unfortunately, it is difficult to draw definitive conclusions from the Luria and Vogel (2014) study because of the potential confound of number of movement paths shown during the study phase. The condition with two bicolor objects had half as many movement paths to track during encoding as the condition with four single-color objects, which may have contributed to the benefit they found.
Balaban and Luria (2015) used a similar procedure and manipulation to examine how common fate influences different dimension conjunctions when the features constitute different parts of the object. A common fate cue was introduced in Experiment 2 using 1 second of movement followed by being stationary for 100 ms during the study phase. The two dual-feature objects condition (two objects with both color and orientation on different parts of the objects) showed no differences in behavioral performance compared with the four single-feature objects condition, suggesting no object benefit was present. Balaban and Luria (2015) also tested color–shape conjunctions in a third experiment. The shape property was a formed by a solid black outline, and the color property was a blob-like color patch. In this experiment, the dual-feature objects appeared as a shape outline on top of a color blob. Movement during study was used to cue common fate for dual-feature objects, whereas single-feature objects moved independently of one another. Contrary to the findings for color orientation, in this experiment, the two dual-feature objects condition showed better recognition accuracy compared with the four single-feature objects condition, but worse accuracy for the two single-feature objects condition. These data support the conclusion of an object benefit, aside from the previously mentioned confound created by the number of movement paths. The condition showing feature convergence during the study display had better recognition accuracy than the four single-feature objects condition did.
The studies outlined above show mixed results for a performance benefit when participants attempt to remember features from multiple parts of objects versus disjunction control conditions where the parts were presented as separate objects. There are two plausible explanations for this inconsistency. First, it is possible the display conditions have a strong impact on whether features from multipart objects are remembered in parallel and at little to no performance cost. A second possibility is that multipart objects do not get the same performance benefit seen for memory of objects with a single part or surface, and the few experiments showing a clear benefit for multipart objects were flawed in some way or are statistical anomalies. Of the studies reviewed, only three conditions show a clear object benefit.
The two conditions Xu (2002a, 2002b) reported that featured a cap or circle indicating color with an attached stem indicating orientation showed a clear performance benefit, but this finding may deserve some skepticism when considering the concerns of Delvenne and Bruyer (2006) and the conflicting results of the color–shape conjunction study reported by Xu (2006). However, these conditions cannot be dismissed outright, because Delvenne and Bruyer’s (2006) replication with additional controls still found a significant object benefit. The effect was much attenuated, and it is not clear if the control was completely effective in eliminating the use of a global position change. The only other study showing a clear object benefit for multipart objects is Balaban and Luria’s (2015) shape–color conjunction condition, and even this finding is somewhat questionable when one considers the stimuli used in the study. Once the outlines used to indicate shape were in the same position as the color blobs, as in the conjunction condition they tested, participants could conceivably attend to the surface within the outline and ignore the parts of the color blob beyond the shape outline. If so, participants would be able to process all task-relevant information from a single part of the object. It is not clear whether or not this strategy was used.
Alternatively, explanations for why an object benefit was not found for other conditions could be made. Although common fate is a strong cue of object structure, it may not completely disambiguate the figure–ground organization of the color-orientation conjunction stimuli used by Balaban and Luria (2015). Common fate is not immediately evident at the onset of the display. If participants initially perceive the object parts as distinct, they may have to try overwriting this initial organization after the common fate cue has become clear. Also, common fate does not necessitate that two distinct surfaces are connected or that they occupy the same depth plane (that is, belonging to the same continuous surface). If selecting and representing a multipart object in memory as a unified item is effortful and nonmandatory, these details could be important when looking for an object benefit in memory performance with these types of objects. More evidence is needed to determine if multipart objects yield the same feature memory benefit seen for single-part objects, so we report several experiments here that use novel display organizations of multipart objects to further explore the possibility of a performance benefit. The following experiments examine how visual short-term memory for multipart objects is influenced by stimulus factors effecting how features making up the objects are integrated within the object (e.g., perceived three-dimensionality, whether the feature is a hole in a surface) as well as the context in which memory for them is tested (e.g., the same number of display items during test as study vs. a single test item) to address the impact of global spatial layout.
Experiment 1
The first experiment explores this problem by testing memory for multipart objects, where color is indicated by one part and orientation is indicated by another part. A key display condition uses monocular depth cues to cause the multipart objects to appear as an unambiguously cohesive entity. Depth cues have the advantage of being immediately apparent upon perception of the objects and being continuous throughout the entire display period. If no object benefit is observed for these stimuli, it would provide evidence against the display ambiguity explanation of the mixed results observed in previous studies.
Method
Participants
A large effect size (partial η2 = .25) was expected for this experiment and all further experiments, so a power analysis conducted in G*Power 3.1 suggested a sample size of 20 participants (Faul, Erdfelder, Lang, & Buchner, 2007). Similar previously conducted experiments have used sample sizes near this number and below, so we elected to gather samples large enough to have n = 20 to 25 after dropping participants based on our rejection criteria. For Experiment 1, a sample of 27 individuals was tested in four within-subjects conditions. All participants were volunteers from the University of Georgia research participant pool and had normal or corrected-to-normal visual acuity and color vision. Participants also reported no history of attention-deficit disorder. The study was approved by the UGA Institutional Review Board, and informed consent was obtained from all participants.
Stimuli
Study and test arrays used in the experiment were created in Adobe Photoshop CS6. Possible object colors included magenta (RGB: 255, 125, 255), yellow (RGB: 210, 210, 40), green (RGB: 0, 190, 0), cyan (RGB: 0, 220, 210), blue (RGB: 81, 81, 255), and brown (RGB: 190, 121, 61). Possible orientations included 30°, 60°, 90°, 120°, 150°, and 180°. Colors were indicated by circular figures occupying 2° visual angle, and each orientation was indicated by a white bar occupying 2° × .34° visual angle. To construct the study displays, colors and orientations were randomly selected without replacement so that no color or orientation could appear twice within the same display. Test probes with a change always involved a change to one of the colors or orientations not shown in the study display for that trial. Also, orientation changes always involved a change of at least 60° to be more similar to the orthogonality of color changes. This minimum change parameter placed some constraint on what orientations could be probed with a change at test. For example, if 30°, 90°, 120°, and 150° orientations were displayed at study, then it was be impossible to probe orientation memory for the 30° item since the remaining two orientations would provide less than a 60° change. Hypothetically, a participant who realizes this could ignore the 30° item in such a situation since it was guaranteed not to change, but the ability to recognize this rule within the experiment and effectively use it to alter performance seems highly unlikely given the rapid speed of stimulus presentation and the high cognitive load incurred by the task.
Spatial locations for the presentation of these stimuli was pseudorandomly selected from 16 possible locations within an 11° × 11° invisible square grid at the center of the monitor. Each possible location within the grid ensured stimuli were no closer than 1° visual angle, edge to edge. Global spatial expanse of the stimuli in the array was controlled to be largely equivalent across conditions by ensuring that each quadrant of the grid (consisting of four possible stimulus locations) contained only one orientation bar and one colored circle. This control was executed during stimulus creation by first randomly selecting a quadrant and then randomly selecting one of the four locations within that quadrant to place a target stimulus. Once a quadrant contained a colored circle and orientation bar it, was no longer available for placement of a subsequent stimulus. In all conditions, study and test arrays were presented with a gray background (RGB: 127, 127, 127) and a central black fixation cross.
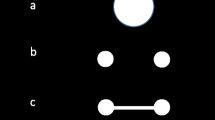
Four different display types that organize the colors and orientations into different configurations were tested (see Fig. 1 for examples). In all display conditions, four white orientation bars and four colored circles were displayed in each memory trial’s study array. A flat condition had each orientation bar centered onto a colored circle so that the eight task-relevant features created four flat multipart objects at four spatial locations (or four occlusion events of the white rectangles appearing in front of the colored circles, depending on subjective interpretation). A depth condition was similar to the flat condition, except a cropped radial luminance gradient was applied to the surface of each feature pair to create the appearance of a sphere-like object instead of a flat circle. Additionally, the orientation bars in this condition were modified so that they taper slightly on their ends to be consistent with the linear perspective of a three-dimensional object receding into depth.Footnote 1 A performance comparison between the flat and the depth conditions will determine if removing figure–ground ambiguity reveals an object benefit for the depth condition. A separate condition showed all circles and orientation bars in separate spatial locations in the array. This condition will serve as a baseline to determine whether or not any object benefit is present for the flat or depth conditions. An overlap condition was also included to control for the possibility that any performance improvement seen in the flat or depth conditions compared with the separate condition is simply due to closer local spatial proximity of the features, rather than the stimuli appearing as unified objects. This condition was designed to have the circles and rectangles appear as though they were simply occluding one another and not part of the same unified object. The overlap condition displayed each orientation bar partially overlapping with the edge of each colored circle in the same quadrant location. The orientation bar could overlap the circle in the top left, top right, bottom left, or bottom right edges of the circle. The orientation bar was centered on the same point of the circle edge for all orientations. Special precaution had to be taken to preserve the minimum 1° visual angle spacing for this condition due to the orientation bars protruding from the circles. When stimuli were randomly selected to appear in positions adjacent to one another, the orientation bars could only be selected to appear on the side of the circles away from the adjacent circle. Otherwise, location of the orientation bar overlap was randomly selected from the four possible positions.

Examples from the four display types tested in Experiment 1 and the trial procedure for the full probe condition. The partial probe condition (Experiment 2) was identical, except the stimuli in only one quadrant of the display appeared at test (i.e., one color and orientation pair). (Color figure online)
Design and procedure
A change-detection paradigm was used to assess memory performance. In each trial, participants were shown a study array for 500 ms followed by a brief retention interval (1,000 ms), during which the screen turned black. After the retention interval, a test probe appeared that was either identical to the study array or had a change to one of the colors or orientations previously shown. The test probe remained visible until the participants made a response of 1 (“no change”) or 2 (“change”) using a keyboard. Visual feedback indicating a correct or incorrect response was given after each response. After the feedback, a gray screen with a central black fixation cross appeared for 3 seconds to allow the participant to reorient themselves for the next trial. Participants were asked to fixate on the central cross during this intertrial interval, as well as during presentation of the study and test arrays. Each trial was viewed on a 37.5-cm × 28-cm CRT monitor screen with a resolution of 1,600 × 1,200 pixels. Participants sat at a distance of 80 cm with their head in a chin rest. Lighting in the experiment room was dim to encourage participants to attend only to the computer monitor, and an experimenter sat quietly behind the participant to ensure they focused on the task.
Each participant was tested in all four display conditions, and conditions were run in four randomized blocks of seven practice trials and 80 experimental trials. Each display condition block consisted of 40 “same” trials in which the test probe was identical to the study array, 20 “change” trials in which a color was changed in the test probe, and 20 “change” trials in which an orientation was changed in the test probe. Prior to each block’s practice trials, participants were given a slowed demonstration of a no-change trial, a color-change trial, and an orientation-change trial while the experimenter explained the task instructions. This procedure was conducted to train participants on what type of difference they should try to detect. Participants were instructed that both types of changes were equally probable and important to the task and that no preference should be given for remembering one feature type over the other.
Results and discussion
A common measure of performance for proponents of slot models of VSTM is K, an estimate of item number capacity. It has been recommended to use a separate formula for full-probe tasks (where all items reappear at test) and single-probe tasks (where only one item reappears at test; Rouder, Morey, Morey, & Cowan, 2011). However, both formulae contain a term corresponding to the number of items in the display, typically interpreted as the number of objects. The current study uses display conditions where this number is ambiguous and likely differing between display conditions, so we were not inclined to use a measure of performance that assumes objects are the basic unit of visual memory. Using percentage correct as an index of performance is also likely to be problematic because of potential response bias differences across display conditions. The different display conditions have a very different perceptual character, so participants may adopt a more conservative or more liberal strategy depending on display condition. Therefore, we decided to use a sensitivity index from signal detection theory to compare performance. The standard index of sensitivity, d′, is only invariant to response bias when the signal and noise distributions are normal and have equal standard deviations (Stanislaw & Todorov, 1999). Neither of these assumptions could be verified in the current study, so a nonparametric measure seemed most appropriate. The most commonly used nonparametric measure of sensitivity is A′ (Pollack & Norman, 1964), which is commonly assumed to be the average of the maximum and minimum area under proper ROC curves that could pass through a given point in ROC space. However, Zhang and Mueller (2005) show that this is a widespread misunderstanding, and they report the correct formula for the average of the maximum and minimum area and named this sensitivity index A (see their paper for a more detailed account). Hit rates and false-alarm rates were used to calculate the nonparametric sensitivity index A for each participant in each of the four conditions (Zhang & Mueller, 2005):
where H is the hit rate and F is the false-alarm rate. Participants were dropped from analyses if their A value was below .5 for any of the four conditions. This criterion was chosen since A = .5 reflects chance performance, while A = 1 reflects perfect performance. No participants were excluded from this experiment. Since A is an unusual measure of performance for VSTM studies (although, A′ has been used occasionally), we also performed analyses using percentage correct and report when results for A and percentage correct differ for the sake of transparency. However, as mentioned already, percentage correct does not account for response bias differences between conditions.
The mean A values for each condition and their standard errors are shown in Fig. 2. A repeated-measures ANOVA was used to compare sensitivity across the four display conditions. Mauchley’s test of sphericity suggested this assumption was unlikely to be violated by the data, p = .808, and data were assumed to be normally distributed and observations independent. The repeated-measures ANOVA was found to be significant, F(3, 78) = 8.832, p < .001, partial η2 = .254, suggesting there was a difference in performance depending on display condition. The Bonferroni–Holm sequentially rejective procedure was used to correct for multiple comparisons between the four display-type conditions (Holm, 1979). Pairwise comparisons showed that the depth condition performed significantly worse than the flat condition (p < .001), the overlap condition (p = .001), and the separate condition (p < .001). No other comparisons reached significance: flat versus overlap, p = .621; flat versus separate, p = .530; overlap versus separate, p = .965. These findings for A match those using percentage correct.

Means and standard errors for Experiments 1 and 2
The results of Experiment 1 provide evidence against the hypothesis that display ambiguity is responsible for nullifying an object benefit for multipart objects in VSTM. Interestingly, these data suggest there is a significant memory disadvantage for the depth condition compared with all other tested display types. This finding is unexpected given that past research has suggested the possibility of an object benefit for memory performance in similar paradigms using single-part objects. One plausible explanation for why the depth condition produced lower performance is due to the additional perceptual complexity of the objects. The luminance gradient slightly alters the appearance of the colors. Also, the slight contour curvature on the orientation stripes may hinder orientation perception. However, colors were selected to be highly differentiable both with and without the luminance gradient during stimulus design and the alteration to the orientation stripes is very minimal. Regardless, it is possible that perceptual factors hindered performance in the depth condition enough to obscure any benefit from the object status of the stimuli.
Another possibility is that performance in the depth condition was worse because the circle and bar appearing to belong to the same surface actually hindered the use of changes in the global spatial layout of the display when participants were trying to detect orientation changes. Experiment 2 was designed to address this possibility.
Experiment 2
Delvenne and Bruyer (2006) and Delvenne, Braithwaite, Riddoch, and Humphreys (2002) showed that surrounding orientation targets with a circle or square hindered change-detection performance. It was hypothesized that orientation changes could be detected as changes in the relative position of the object in the array rather than changes in a local object property. Studies by Delvenne and colleagues showed that surrounding the objects with a border seems to cause perceived position changes to be local to within the border, negating the use of perceived changes in position relative to other items in the display. An orientation change to an object in the depth condition of the Experiment 1 is potentially seen as a rotation of a holistic striped sphere and not a change in relative position of the orientation-bearing surface, independent of the color-bearing surface. Similarly, the object appearance might encourage a greater reliance on local rather than global deployment of attention. The other three conditions do not elicit the same perception of object cohesiveness, so it may be easier to use perceived global position change to improve performance in those conditions. The flat condition is the next most object-like configuration, but, as discussed earlier, it is possible to perceive the orientation bars as being in a different depth plane than the circles. This perception may be why performance is not similarly impaired as in the depth condition. Orientation stimuli used by Delvenne and Bruyer (2006) and Delvenne et al. (2002) never featured an enclosure that extended behind the orientation-bearing surface like stimuli in the flat condition, so it is unclear if the enclosure effect observed in their studies would carry over to the flat condition. Both explanations offer a possible account of the data, so Experiment 1 was replicated with one procedural change. Participants were tested using identical stimuli and procedure, with the exception that a partial test probe was used instead of a full test probe (i.e., a single color and orientation pair reappeared at test rather than all the items). The use of a partial probe removes the global spatial context from the items at test; therefore, the ability to detect orientation changes based on perceived relative location changes is disrupted. Full probe versus partial probe procedures compared in the past have shown a memory advantage for binding information (i.e., which features were on which object), but no difference for features (Wheeler & Treisman, 2002). The difference in binding memory should not be relevant to the current study since this aspect of the objects is not being tested.
Method
Participants
A sample of 29 individuals from the University of Georgia research participant pool volunteered for and participated in this study. All participants had normal or corrected-to-normal visual acuity, normal color vision, and no reported history of attention-deficit disorder. The study was approved by the UGA Institutional Review Board, and informed consent was obtained from all participants.
Stimuli
Stimuli were identical to those used in Experiment 1.
Design and procedure
Design and procedure were identical to Experiment 1, except that partial test probes were used instead of full test probes. Partial probes showed only one of the four local feature pairs (color and orientation) that were shown at study. For the flat, depth, and overlap conditions, this meant one of the four local feature pairs were randomly selected to reappear at test. For the separate condition, the items in one randomly selected quadrant of the display reappeared at test.
Results and discussion
The results of the partial probe task are shown in Fig. 2. A 4 × 2 mixed ANOVA, with display type (depth, flat, overlap, and separate) and test probe type (full and partial) as the independent variables, was conducted to compare the effects from Experiment 1 with those of Experiment 2. Mauchley’s test of sphericity (p = .946) and Levene’s test of equality of error variance (depth, p = .391; flat, p = .541; overlap, p = .973; separate, p = .905) were not significant, verifying that these assumptions of the data were likely to be met. The mixed ANOVA showed a significant interaction of display type and probe type, F(3, 162) = 12.860, p < .001, partial η2 = .192, suggesting the effect of display type was different for the two probe types. There was also a significant main effect of display type, F(3, 162) = 6.940, p < .001, partial η2 = .114, and probe type, F(1, 54) = 4.414, p = .040, partial η2 = .076. We proceeded with pairwise comparisons using the Bonferroni–Holm method to examine the differences between display type for the partial-probe condition. These comparisons showed the separate condition yielded worse performance than all other conditions (ps < .001), while no other comparisons reached significance (depth vs. flat, p = .922; depth vs. overlap, p = .531; flat vs. overlap, p = .507). These findings for A match those using percentage correct. These data show a substantially different performance trend than the full probe data. Sensitivity in the depth condition is no different from that in the flat and overlap conditions when global spatial context is unavailable at test. This result indicates the perceptual complexity explanation is not a valid account of the low performance in the depth condition in the full probe version of the experiment. If perceptual complexity was impairing memory before in the depth condition, this effect should carry over to the partial probe version of the task. Instead, it appears more likely that performance in the depth condition was lower because of a hindered ability to use the global spatial context to detect orientation changes due to the more connected appearance of the color and orientation features. In contrast to the hypothesized object benefit for multipart objects in VSTM, it appears this study has revealed a sort of object detriment to performance.
The separate condition in the partial probe version of the experiment yielded lower performance than the other display types. The fact that the overlap condition yields similar performance to the flat and depth conditions suggest this advantage is over the separate condition is not due to the surface pairs appearing as a unified whole. Instead, this performance difference is likely due to the difference in local spatial proximity of color and orientation-bearing surfaces between the separate condition and the other display types. Without the use of global spatial context, participants most likely rely more on local pairings to optimally perform the task. This effect may reflect a change from a more distributed deployment of attention to a more localized deployment to each feature location. The separate condition contains more task-relevant locations to attend, and performance appears to have suffered as a result.
Experiment 3
Experiments 1 and 2 provide evidence against the hypothesis that visual features organized into multipart objects are more easily remembered than if they are perceived as belonging to distinct objects. The use of a luminance gradient and linear perspective should have indicated to participants that both the orientation bar and the colored ball are part of the same continuous object surface. However, the occlusion/figure–ground ambiguity problem is only inherent to previously tested multipart objects because they have an additional surface feature. Displays used to test multipart object memory thus far are constructed in a similar way, essentially adding an additional surface feature distinguished by a color change. One reason why an integration benefit is not possible for these objects could be that the human VSTM system is limited by the number of distinct surfaces, regardless of their perceived connectedness, that can be selectively encoded and maintained.
Consider that for each distinct surface there are a number of visual features that are inherent to it. Size, orientation, shape, and color are all visual characteristics of an object that are defined by the expanse and quality of its surface and are available in parallel during perception of the surface. It would be reasonable if these same features were stored in parallel as part of our memory of the characteristics of the object’s surface. Encoding an additional surface could result in lower performance because characteristics of each surface must be represented as being distinct from one another, requiring more attentional effort. One query that would help define the limitations of object representation in VSTM is assessing how features inherent to holes within objects would be treated compared with features inherent to an additional surface on that object. What if the orientations of the objects used in Experiment 1 were indicated by the orientation of a hole within the object rather than a stripe? If the difficulty in multipart object memory is due to the necessary representation of multiple surfaces, orientation and color should be remembered more efficiently for objects whose orientation is indicated by a hole because both features are characteristics of the same hole-bearing surface. This type of object could be compared with objects where orientation and color are encoded from single-surface rectangles, a structure that tends to be remembered better than when the same number of orientations and colors are presented on different surfaces. However, different from single-surface rectangles, a circular object with a rectangular hole could still be considered a “multipart” object since the orientation feature is inherent to an additional boundary contour.
Holes and surfaces
For the purposes of the current experiment, holes will be used because they are an additional object boundary that does not create an additional surface on the object. There is a body of literature on the perception of holes and their relation to the objects that contain them. The Gestalt idea of unidirectional contour ownership suggests contours define the shape of figural surfaces while ground regions are essentially shapeless (Koffka, 1935; Rubin, 1921). However, intrinsic holes, those defined by a contour occurring entirely within a figure region, have been shown to have properties different than traditionally defined ground regions. The shape of an intrinsic hole has been shown to be perceived and remembered as well as that of an object, even when hole shape memory is probed with objects (Palmer, Davis, Nelson, & Rock, 2008). In contrast, the shape of accidental holes, formed by the overlap of more than one figural region in different depth planes, and other ground regions are not remembered well (Nelson, Thierman, & Palmer, 2009). Palmer and colleagues suggested that objects with intrinsic holes are encoded as the shape of the material surface of the figure as well as the shape of the immaterial surface of the hole. The immaterial hole is thought to be somehow symbolically tagged with an “empty” label to indicate it represents an absence of material. Furthermore, intrinsic holes are an integral part of the object that forms them and are “an aspect of this hole-bearing object” (Nelson et al., 2009, p. 206).
This conceptualization of intrinsic hole perception is explicit in the unity of the hole and hole-bearing surface, but still suggests holes are treated in a surface-like way, albeit an immaterial surface. It is not clear from the descriptions given whether or not an immaterial surface would be expected to be treated similarly to a material surface by the VSTM system; however, this consideration may not be an issue. Work by Bertamini and his colleagues has provided considerable empirical evidence against the idea that intrinsic holes are represented like figures and is consistent with the principle of unidirectional contour ownership. For instance, one study showed that a judgment advantage for the position of boundary contour convexities depended directly on whether an area defined by the contour was perceived as a figural surface or a hole within a figural surface (Bertamini & Croucher, 2003). This study provides evidence for contour ownership belonging to the figure, and the authors conclude that hole shape is known indirectly as an inherent part of the figure’s surface. A more recent study by Bertamini and Helmy (2012) used a flanker task in which participants judged whether or not a figure was a square or circle. Within the target figure was either a square hole or a square figure. The logic of the task was that if the hole cannot be processed independently of the target figure, it should create interference when there is a mismatch between the hole shape and target figure shape. The same interference should not be seen when there is a mismatch between the occluding figure and the target figure because they are represented as being distinct entities. The results of the study showed exactly this pattern. The authors suggest this study and others show that an intrinsic hole is not processed in the same way as a figure; rather, it is processed incidentally of the figure that forms it. If this characteristic of how intrinsic holes are processed carries over to their representation in short-term memory, and the number of surfaces is a critical factor in VSTM capacity, visual features of a hole-forming contour would be expected to be encoded and maintained more easily than features from a contour creating an additional figural surface.
Method
Participants
A sample of 62 individuals from the University of Georgia research participant pool volunteered for and participated in this study. All participants had normal or corrected-to-normal visual acuity, normal color vision, and no reported history of attention-deficit disorder. The study was approved by the UGA Institutional Review Board, and informed consent was obtained from all participants.
Stimuli
Study and test arrays for four display conditions (hole, surface, combined, and separate) used in the experiment were created in Adobe Photoshop CS6 (see Fig. 3 for examples). Possible object colors for all conditions included magenta (RGB: 255, 125, 255), yellow (RGB: 210, 210, 40), green (RGB: 0, 190, 0), cyan (RGB: 0, 220, 210), red (RGB: 215, 75, 75), and orange (RGB: 245, 140, 20). Possible orientations included 30°, 60°, 90°, 120°, 150°, and 180°. Color was indicated by a circle occupying 2° visual angle for the hole, surface, and separate conditions. Orientation was indicated by a rectangular bar occupying 1.5° × .4° visual angle in the surface, combined, and separate conditions. The color feature for the combined condition was also indicated by the rectangular bar. For the hole condition, orientation was indicated by a hole within the colored circles that was identical in shape to the rectangular bar in the other conditions. The contour indicating orientation was slightly undulated to create a globally concave shape. Work by Arnheim (1954) and Kanizsa and Gerbino (1976) has shown that globally concave shapes are more easily seen as holes. This feature was kept consistent in the other conditions since the contour creating the orientation feature in those conditions was unambiguously not creating a hole due to the orientation-bearing surface being a different color than the background.

Examples from the four display types tested in Experiment 3 and the trial procedure for the full probe condition. The partial probe condition was identical, except the stimuli in only one quadrant of the display appeared at test (i.e., one color and orientation pair). (Color figure online)
To construct the study displays, colors and orientations were randomly selected without replacement so that no color or orientation could appear twice within the same display. Test probes with a change always involved a change to one of the colors or orientations not shown in the study display for that trial. Also, orientation changes always involved a change of at least 60° to be more similar to the orthogonality of color changes. Spatial locations for the presentation of these stimuli was pseudorandomly selected from 16 possible locations within an 11° × 11° invisible square grid at the center of the monitor in the same manner as Experiment 1. Each possible location within the grid ensured stimuli were no closer than 1° visual angle, edge to edge. In all conditions, study and test arrays were presented with a gray background (RGB: 127, 127, 127) speckled with black markings to create a texture that was visible through object holes.
Design and procedure
The trial procedure and display parameters were identical to that of Experiments 1 and 2. Performance in four different display-type conditions (manipulated within subjects) was compared to determine if color and orientation sensitivity depended on how the features were configured into objects. Additionally, Experiment 3 tested all four display-type conditions using both a full and partial probe (probe type was manipulated between subjects) since these two conditions yielded different outcomes between Experiments 1 and 2 and proved useful in interpreting the results. Within the two probe-type conditions, the order individuals completed each display-type condition was randomized.
The surface condition was similar to the flat condition of Experiments 1 and 2, except that the orientation bar did not extend to the border of the circle. This change was made to make it identical in size and shape to the orientation hole in the hole condition. The second comparison condition was the combined condition. This condition displayed both color and orientation features on the same surface, identical in size and shape to the holes in the hole condition and the bars in the surface condition, and with one boundary contour. These simple objects will be similar to those used in experiments yielding an object benefit for memory performance. Performance in the combined condition will thus serve as a reference point for an object benefit in the current study. The last comparison condition is the separate condition. This condition will display color bearing surfaces and orientation bearing surfaces in separate locations.
Results and discussion
As in Experiments 1 and 2, hit rates and false-alarm rates were used to calculate A for each condition, and the same exclusion criteria were used for participant data. For the full-probe condition, data from 33 participants were initially collected, but one participant was excluded because of missing data. For the partial-probe condition, data from 29 participants were collected, and one participant was excluded from final analyses because of low performance (A < .5) in one of the conditions (final n = 28).
Means and standard errors for each condition are shown in Fig. 4. A 2 × 4 mixed ANOVA was conducted to compare performance between the full and partial-probe conditions. Mauchley’s test of sphericity was not significant, p = .882, and Levene’s test of equality of error variances was not significant for any display condition (hole, p = .105; surface, p = .909; combined, p = .391; separate, p = .442). Critically, there was a significant interaction of display condition and probe condition, F(3, 174) = 10.707, p < .001, partial η2 = .156, suggesting performance in the different display conditions varied between probe conditions. There was also a significant main effect of display condition, F(3, 174) = 27.512, p < .001, partial η2 = .322, and probe type, F(1, 58) = 19.204, p < .001, partial η2 = .249. For the full-probe condition, a repeated-measures ANOVA was used to test for differences in A between the different display conditions. Mauchley’s test of sphericity was not found to be significant, p = .204, so analyses proceeded without correction. The ANOVA showed a significant difference between display conditions, F(3, 93) = 21.273, p < .001, partial η2 = .407. Pairwise comparisons using the Bonferroni–Holm method showed performance in the combined condition was significantly greater than the hole, separate, and surface conditions (ps < .001). All other conditions were not significantly different from one another (hole vs. surface, p = .177; hole vs. separate, p = .736; surface vs. separate, p = .205). A repeated-measures ANOVA was also conducted for the partial-probe condition. Mauchley’s test of sphericity was again found to be nonsignificant, p = .384, so analyses assumed sphericity of the data. The ANOVA for the partial-probe condition was significant, F(3, 81) = 17.018, p < .001, partial η2 = .387, indicating differences in performance for the four display types. Pairwise comparisons revealed that performance in the separate condition was significantly lower than the all other conditions (ps < .001) and that no other conditions were significantly different from one another: hole versus surface, p = .213; hole versus combined, p = .037 (adjusted α = .017 for this comparison); surface versus combined, p = .151. Findings for both the full and partial-probe conditions were consistent for both A and percentage correct.

Means and standard errors for Experiment 3
Similar to the differences between Experiments 1 and 2, the results of Experiment 3 present a substantially different pattern of findings depending on whether a full test probe or a partial test probe was used. The combined condition yielded better performance for the full-probe condition than all other display types, while the separate condition yielded worse performance than all other display types for the partial-probe condition. Of particular interest, the hole condition does not appear to yield any difference in performance from the surface condition for either probe type. This result seems to support the main findings of Experiments 1 and 2: Multipart objects do not yield any memory performance benefit beyond local feature proximity, regardless of their perceived unity.
One possible reason for this outcome is that features of the holes within the objects are encoded in VSTM distinctly from the features of the hole-bearing surface. Holes might be effectively treated as a second object surface in VSTM, and thus performance in the hole condition would not be expected to differ from that of the surface condition. This explanation could be why Palmer et al. (2008) found memory for intrinsic holes to be as good as memory for objects, but it seems inconsistent with the findings of the flanker task used by Bertamini and Helmy (2012) and the contour judgment task used by Bertamini and Croucher (2003). However, this inconsistency is easily explained by the fact that the studies by Bertamini and colleagues were strictly perceptual tasks, while the performance in the current experiment could be influenced by both perceptual and memory processes.
One inconsistency of Experiment 3 is that there is no object detriment for the hole condition using the full probe procedure, similar to that seen in the depth condition for Experiment 1. In Experiment 1, we suggested this performance deficit was due to a reduced likelihood of seeing the orientation changes as position changes relative to the other items in the display. Instead, participants may have interpreted the round objects as rotating holes with radial symmetry rather than independent bars moving toward or away from nearby objects, encouraging the use of a more localized rather than global deployment of attention. This difference could produce a sensitivity difference between the depth condition and the flat and separate conditions of Experiment 1 if participants were able to use the global spatial context to their advantage in these latter display types. One reason why this difference might not be replicated by the hole condition of Experiment 3 is that these stimuli allow for an easier extraction of the global orientation properties in the array. Another possibility is that the significant difference between the depth and flat conditions of Experiment 1 was a Type I error. In light of this possibility, and the fact that this finding is somewhat counterintuitive given the history of object-based performance benefits in VSTM, we conducted a replication of the full-probe condition of Experiment 1 and report the results in Experiment 4.
Experiment 4
One important aspect of Experiment 3 is that the lower performance seen in the depth condition in Experiment 1 did not carry over to the hole condition. The simplest explanation is that the significant difference between the depth and flat conditions of Experiment 1 was simply a statistical anomaly. Experiment 4 attempts to replicate the full-probe condition of Experiment 1 with a new sample of participants.
Method
Participants
A sample of 28 individuals from the University of Georgia research participant pool volunteered for and participated in this study. All participants had normal or corrected-to-normal visual acuity, normal color vision, and no reported history of attention-deficit disorder. The study was approved by the UGA Institutional Review Board, and informed consent was obtained from all participants.
Stimuli, design, and procedure
Stimuli, design, and procedure were identical to those in the full-probe condition in Experiment 1.
Results and discussion
The mean A values and standard errors of the 28 participants are displayed in Fig. 5. A 2 × 4 mixed ANOVA was used to compare performance in the four display conditions between this replication and the original data. Mauchly’s test of sphericity was not significant, p = .609, and Levene’s test of equality of error variance was also not significant for each of the four display conditions (depth, p = .643; flat, p = .692; combined, p = .937; separate, p = .622). The between-subjects effect was found to be nonsignificant, F(1, 53) = .021, p = .886, partial η2 = .000, suggesting there was no difference between the participant groups, collapsed across display type. The main effect of display type was significant, F(3, 159) = 16.113, p < .001, partial η2 = .233. There was no interaction effect, F(3, 159) = .938, p = .424, partial η2 = .017, suggesting performance in the display conditions did not vary across participant groups. A repeated-measures ANOVA was used to compare sensitivity across the four display conditions of the replication data. Mauchley’s test of sphericity suggested this assumption was unlikely to be violated by the data, p = .513. The repeated-measures ANOVA was found to be significant, F(3, 81) = 8.029, p < .001, partial η2 = .229, suggesting there was a difference in performance depending on display condition. Pairwise comparisons were again made using the Bonferroni–Holm sequentially rejective procedure to correct alpha for multiple comparisons (Holm, 1979). These comparisons showed that performance in the depth condition was significantly worse than in the overlap condition (p = .003) and the separate condition (p < .001), and performance in the flat condition was significantly worse than in the separate condition (p = .009). No other comparisons reached significance (depth vs. flat, p = .081; flat vs. overlap, p = .080; overlap vs. separate, p = .390). This was consistent with the findings using percentage correct.

Means and standard errors for Experiment 4
Although a direct comparison across experiments suggested no difference between Experiment 1 and its replication, pairwise comparisons in the replication show a different pattern of results. Primarily, the depth condition did not yield a significantly lower performance than the flat condition. Because the mixed ANOVA showed no significant between-subjects main effect or interaction effect, we decided to combine the data from the original and replication to increase the power of the analysis. A repeated-measures ANOVA of the combined data showed a significant effect of display type, F(3, 162) = 16.191, p < .001, partial η2 = .231. Pairwise comparisons showed performance in the depth condition was significantly lower than in all other conditions (ps < .001). No other comparisons reached significance after adjusting alphas using the Bonferroni–Holm method: flat versus overlap, p = .118; flat versus separate, p = .019 (α = .017 for this comparison); overlap versus separate, p = .536. Results using percentage correct were somewhat different in this case. The depth condition was significantly lower than all other conditions (ps < .001), but the flat condition was significantly less than the overlap (p = .016) and separate (p = .007) conditions.
The results of this replication are somewhat mixed. Results of pairwise comparisons in the new sample of participants were not replicated precisely; however, the ANOVA used to compare the two groups suggested there was no significant difference. After combining data from the two samples, the pairwise comparisons are consistent with the results of the original experiment for A, but not for percentage correct. Even for A, the comparison between the flat and separate conditions was very near significance. These findings suggest the observed lower performance in the depth condition may be a weak or somewhat inconsistent effect, which could explain why it was not observed in for the hole condition in Experiment 3.
Returning to the results of Experiment 3, the combined display type of the full-probe condition replicate the general findings of Luck and Vogel (1997) and Olson and Jiang (2002), who found better performance for color and orientation change detection when features were consolidated on the same object surface (colored rectangles) than when spatially separated surfaces indicated color or orientation (colored squares and orientation rectangles). However, the fact that this performance advantage did not translate to the partial-probe condition makes it difficult to interpret as an object benefit. Nothing about the visual characteristics of the items in the combined condition changed between probe-type conditions, so any performance benefit due to the object status of the display items should remain intact. One possibility is that a performance benefit for the partial probe combined condition was present, but it was not detected in the data due to the combining of color and orientation change-detection performance into one sensitivity index. If the performance benefit influenced only orientation or color change-detection performance, but not the other, then it is possible that an effect would be obscured by the averaging of the two change types together. Experiment 4 was conducted to examine this possibility.
Experiment 5
Experiment 5 was designed to be a replication of Experiment 3, but with a slight procedural change to allow for the calculation of a separate sensitivity index for color change and orientation change. The design for the previous experiments did not allow for this because a separate false-alarm rate could not be established for the two types of change. Even for percentage correct, comparing only the hit rates for the two feature types would not provide a valid measure of performance. If color and orientation performance can be examined separately, then it will allow us to evaluate the possibility that an object benefit in the combined condition for Experiment 3 was obscured by the averaging of performance between the two types of change into one sensitivity index.
Method
Participants
A sample of 60 individuals from the University of Georgia research participant pool volunteered for and participated in this study. All participants had normal or corrected-to-normal visual acuity, normal color vision, and no reported history of attention-deficit disorder. The study was approved by the UGA Institutional Review Board, and informed consent was obtained from all participants.
Stimuli
Stimuli parameters for Experiment 5 were identical to those in Experiment 3, with one exception. White speckling was added to black speckling on the gray backgrounds in all display conditions to make sure participants would notice the background texture through the holes.
Design and procedure
The trial procedure and display parameters were identical to that of Experiments 3, except that during the test display the fixation cross was replaced by an “O” or a “C” to indicate to the participant whether they should look for an orientation or color change for that trial. Participants were instructed before they began the task to use the letter displayed at test to make their “change” or “no-change” response. They were told that when an “O” was displayed at test, the only possible change that might have occurred was an orientation change. Similarly, when a “C” was displayed, the only possible change was a color change. Using this procedure forced participants to encode both features into VSTM during study, since the cue was only available at test, but also allowed for the measurement of a separate false-alarm rate and hit rate for orientation and color memory. Half of trials were “O” trials and half were “C” trials, with half being change trials and half being no-change trials. As in Experiment 3, both a full-probe and partial-probe version of the task was tested using two different participant groups. Participants in both probe-type conditions performed each display-type condition in randomized blocks of 80 experimental trials per display type.
Results and discussion
The new procedure allowed for the mean sensitivity index A to be calculated for both types of change; therefore, the new performance criteria for exclusion of participant data in final analyses was A < 0.5 for either change type in any of the four display conditions. Data were collected from 30 participants for the full-probe condition, but four participants were excluded from analyses based on these criteria, and one was excluded due to missing data (final n = 25). For the partial-probe condition, data were also collected from 30 participants, with nine excluded from analyses for low performance, resulting in n = 21. Of the participants excluded for low performance, all but one was excluded due to low performance for only orientation memory. This trend suggests that some participants were using a trade-off strategy to perform the task, where they attempted to only remember one of the two feature types. As mentioned in the design and procedure, participants were explicitly instructed to not use a trade-off strategy and to pay equal attention to both the color and orientation of the objects; however, it appears that some did not accommodate this request, willfully or otherwise, particularly in the separate and hole conditions of partial probe version of the task. Five participants met rejection criteria based on orientation memory performance in the hole condition, and six met rejection criteria based on orientation memory performance in the separate condition (compare this with two in the surface condition and zero in the combined condition). While some participants may have adopted this strategy due to difficulty of the orientation memory task, we do not believe this was the case for the majority. The 21 participants not excluded in the partial-probe condition performed well above chance, with means for the four display conditions ranging from .686 to .817.
We examined color and orientation sensitivity separately for both the full-probe and partial-probe conditions. Data for both feature types, divided by probe and display conditions, are shown in Fig. 6. First, a 4 × 2 repeated-measures ANOVA was conducted on the full-probe data, with display type and feature type as the two independent variables. The assumption of sphericity was not violated, with Mauchley’s test yielding p = .447. There was a significant interaction effect, F(3, 72) = 9.949, p < .001, partial η2 = .293. Main effects for display type, F(3, 72) = 17.538, p < .001, partial η2 = .422, and feature type, F(1, 24) = 67.839, p < .001, partial η2 = .739, were also significant. These findings suggest participants performed better at color memory than at orientation memory, and that the effect of display type was different for the two feature types. Pairwise comparisons using the Bonferroni–Holm method for color change sensitivity in the full-probe condition were not significant. However, the same analyses using percentage correct did show a significantly greater percentage correct for combined compared with separate (p = .007). For orientation change sensitivity in the full-probe condition, pairwise comparisons using the Bonferroni–Holm method showed performance in the combined condition was greater than all other conditions (ps < .001). No other comparisons reached significance: hole versus surface, p = .600; hole versus separate, p = .026 (adjusted α = .017 for this comparison); surface versus separate = .027 (adjusted α = .025 for this comparison). These findings for A were consistent with those for percentage correct.

Means and standard errors for Experiment 5
For the partial-probe condition, we conducted another 4 × 2 repeated-measures ANOVA. Mauchley’s test of sphericity was not significant, p = .487. Results indicated a significant main effect of display type, F(3, 60) = 13.961, p < .001, partial η2 = .411, and feature type, F(1, 20) = 56.666, p < .001, partial η2 = .739. Once again, orientation memory was worse than color memory. The interaction effect was near, but not within, the significance range of p < .05, F(3, 60) = 2.462, p = .074, partial η2 = .110. Due to the near significance of the interaction, and that the purpose of this experiment was to examine display-type effects separately for the two feature types, we elected to perform additional analyses on the feature types, separately. For color change, no pairwise comparisons remained significant after correcting alpha for multiple comparisons: hole versus surface, p = .572; hole versus combined, p = .805; hole versus separate, p = .060, surface versus combined, p = .844; surface versus separate, p = .027 (adjusted α = .008); combined versus separate, p = .038 (adjusted α = .010). These results for A was consistent with the findings for percentage correct. In contrast, orientation change sensitivity had several pairwise comparisons remain significant after applying the Bonferroni–Holm method. Performance in the combined condition was significantly greater than the hole (p = .023), surface (p = .001), and separate (p < .001) conditions. Furthermore, performance in the separate condition was also significantly lower than in the hole (p = .006) and surface (p = .012) conditions. Hole was not different from surface, p = .409. For percentage correct, the findings match those for A before the Bonferroni–Holm adjustment is made, but several comparisons no longer reach significance with the adjusted alpha values. Specifically, the hole versus combined (p = .029, α = .025), hole versus separate (p = .018, α = .013), and surface versus separate (p = .020, α = .017).
The test cue used in Experiment 5 allowed us to examine VSTM sensitivity for color and orientation separately, revealing that the differences in performance observed in the combined sensitivity measure were driven solely by orientation memory. For both the full-probe and partial-probe conditions, there were no differences in performance between display conditions for color change when examining performance using A. Display condition differences for orientation VSTM sensitivity in the full-probe condition matched the differences observed when color and orientation sensitivities were combined; however, this was not the case for the partial-probe condition. Here, we observed that orientation sensitivity in the combined display condition was greater than all other conditions, while orientation sensitivity in the separate display condition was lower than all other conditions. This finding supports the possibility suggested in our discussion section for Experiment 3, that the combined sensitivity measure was not revealing a performance advantage for the combined display condition because it was only present for one of the two tested feature types.
The finding that orientation VSTM drives performance differences between display types seems to support the explanation of our previous results, that global spatial layout of the memory array is used by participants to detect positional changes of the orientation components relative to the other items in the array. However, when global spatial layout is not available at test, as in the partial probe condition, we suggested local feature proximity as the main driver of performance differences across display conditions. For the partial probe condition of Experiment 5, the lower orientation performance of the separate display condition supports this idea, but the higher performance of the combined condition requires some further explanation. There is no substantial difference in local proximity of the orientation and color components of the objects in the hole, surface, and combined conditions, so there must be some selection or retention advantage inherent to the simple objects used in the combined condition. Because of the consistent equivalence in performance in the hole and surface conditions in Experiments 3 and 5, it seems reasonable to assume the VSTM system encodes and/or represents features of intrinsic holes in a similar way to that of surfaces. This could explain why Palmer et al. (2008) found memory for intrinsic holes to be as good as surfaces, whereas Nelson et al. (2009) found memory for accidental holes to be poor. The findings of Bertamini and colleagues discussed earlier may only be relevant to perceptual organization and/or attentional selection, but not short-term memory processes that drive the performance observed in the present experiments.
General discussion
The current study tested the hypothesis that features of multipart objects will be more easily remembered because of their object status if they are unambiguously perceived as connected objects. Overall, the results of the study seem to indicate the perceived connectedness of distinct object surfaces has no benefit for memory performance, but it does seem to indirectly impact performance by influencing use of interitem spatial relationships to detect a feature change. Also, objects whose features are inherent to one surface and one boundary contour do seem to have some benefit over multipart objects that have the same number of task-relevant features distributed across more than one distinctive surface or more than one boundary contour.
Experiments 1 and 2 compared a condition in which depth cues disambiguated the connectedness of the objects to three other conditions. The experiments resulted in the lowest performance for the most unambiguously object-like condition, the depth condition, in the full probe version of the task. The partial probe version resulted in the lowest performance for the separate condition. Research by Delvenne and Bruyer (2006) and Delvenne et al. (2002) is consistent with the idea that this pattern of performance may be due to the use of the global spatial layout of the display to aid in orientation detection performance for the full probe condition. The global spatial layout was unavailable at test during the partial probe condition, so participants were likely more reliant on local feature proximity to make change judgments rather than detecting orientation changes through a change in relative spatial proximity between the orientation bar and nearby items. In the full probe version of the task, performance may be lower in the depth condition because the depth cues connecting the orientation bar to the colored circle caused greater difficulty in the use of global spatial changes associated with an orientation change. Figural structure in the other conditions did not have the same level of perceived connectedness, so orientation bars could easily be seen as a change to a global property of the display. Thus, the lower performance in the depth condition may be a sort of object detriment for change detection performance. The partial probe version of the task shows no difference in performance for the flat, depth, and overlap display conditions, while the separate condition yields the lowest performance. The common characteristic of the three equivalent conditions is the close local proximity of the feature pairs that seems to yield a grouping advantage that translates to better feature change sensitivity.
Experiment 3 also attempted to test the object ambiguity hypothesis by disambiguating the objects using a hole within the object, created by an additional internal boundary contour, to indicate a secondary feature rather than an additional surface. The full probe condition of Experiment 3 yielded greater performance for the combined condition compared with the other three. The partial probe version yielded lower performance in the separate condition and no difference in performance for the other three. Once again, object ambiguity seemed to play no role in memory performance. The hole objects imparted no performance advantage over the surface objects, despite the feature bearing components of the object appearing unambiguously connected. Experiment 3 showed that multipart objects do not impart a VSTM performance advantage in the way previously shown for single-part objects, even when the additional “part” is a boundary contour rather than a surface. We suspect that the VSTM system is taxed similarly when maintaining a memory for features of an intrinsic hole as it is when maintaining features of an object surface.
Experiment 3 showed no performance disadvantage for the hole condition like that of the depth condition in Experiment 1. We suspect that this effect did not carry over to the hole condition because the spherical, three-dimensional aspect of the stimuli in the depth condition was critical to the effect. The depth objects had a very ball-like appearance that would have increased the plausibility of a perception of unified rotation of both the orientation stripe and the colored ball surface. Experiment 4 replicated the full probe condition of Experiment 1 to see if this effect was robust and found that a new set of participants did not produce the same result; however, combining the original data with the replication data did produce the same detriment in performance for the depth condition that was originally found. It should be noted that this effect, while interesting, is likely to be weak and fairly specific to the experimental conditions of this study.
A surprising finding of Experiment 3 was that, for the partial probe condition, the combined display condition did not yield a significant performance advantage over the hole and surface conditions. We hypothesized that this was due to the performance difference being attenuated by the use of a combined sensitivity index for both color and orientation change. Experiment 5 revealed that this was the case by using a trial procedure that allowed calculation of a separate sensitivity index for the two change types. Looking at orientation change sensitivity alone revealed a performance advantage for the combined condition using the partial-probe procedure. This result indicates a performance advantage for remembering multiple features when they are inherent to a single surface and single boundary contour object as opposed to remembering the same features when they are inherent to different object surfaces, an object surface and an intrinsic hole within the object, or different objects.
Overall, the results indicate that perceived connectedness of multipart objects can influence VSTM (shown by the depth condition), but it appears to be driven solely by how the object organization encourages or discourages the use of ensemble spatial relationships to select, group, or identify global changes in visual information. The use of group information to make a memory judgment is well documented in the VSTM literature (Alvarez, 2011; Alvarez & Oliva, 2009; Brady & Alvarez, 2011; Brady, Konkle, & Alvarez, 2011). Participants in the current study are presented with the difficult task of remembering eight visual features distributed across four to eight spatial locations, depending on display condition. It is not surprising that, when possible, they would rely heavily on changes to the ensemble statistics of the displays to determine whether a change had occurred because these global characteristics are represented with minimal attention demands (Alvarez & Oliva, 2009). Interestingly, how those features are configured into objects seems to influence how easy or difficult it is to use ensemble information.
This conclusion is consistent with the global spatial change interpretation of the object benefit found for the two stimulus types used in Xu (2002a, 2002b) with colored heads and orientation tails. It seems likely that no such benefit would be found if a partial probe procedure was used to force participants to rely on independent object representations, but further experiments would be necessary to confirm this prediction. The only other multipart object configuration that reported a clear object benefit, to our knowledge, is the color–shape stimuli used by Balaban and Luria (2015). As discussed earlier, the structure of these objects does not necessitate that the task-relevant features be perceived and represented as different parts of the object. The color surface extending underneath the shape-bearing boundary contour does not contribute additional task-relevant information beyond what can be perceived from the internal color surface. These potential alternative explanations for previously reported memory benefits for multipart objects and the results of the studies reported in this paper lead us to conclude that it is unlikely that multipart objects impart the same or a similar VSTM benefit as that previously observed for single-part, simple objects, regardless of their perceived unity or cohesiveness.
Data for all experiments are available at https://github.com/bmcdunn87/VSTM_multipart_objects_2019.
Notes
Pilot data collected from a separate group of participants indicated that these Depth stimuli were indeed seen as having more depth and appeared more three-dimensional than any of the other conditions’ stimulus configurations.
References
Aginsky, V., & Tarr, M. J. (2000). How are different visual properties of a scene encoded in visual memory. Visual Cognition, 7(1/3), 147–162. doi:https://doi.org/10.1080/135062800394739
Allport, D. A. (1971). Parallel encoding within and between elementary stimulus dimensions. Perception & Psychophysics, 10(2), 104–108. doi:https://doi.org/10.3758/BF03214327
Alvarez, G. A. (2011). Representing multiple objects as an ensemble enhances visual cognition. Trends in Cognitive Sciences, 15(3), 122–131. doi:https://doi.org/10.1016/j.tics.2011.01.003
Alvarez, G. A., & Oliva, A. (2009). Spatial ensemble statistics are efficient codes that can be represented with reduced attention. Proceedings of the National Academy of Sciences of the United States of America, 106(18), 7345–7350. doi:https://doi.org/10.1073/pnas.0808981106
Arnheim, R. (1954). Art and visual perception. Berkeley, CA: University of California Press.
Awh, E., Barton, B., & Vogel, E. K. (2007). Visual working memory represents a fixed number of items regardless of complexity. Psychological Science, 18(7), 622–628. doi:https://doi.org/10.1111/j.1467-9280.2007.01949.x
Balaban, H., & Luria, R. (2015). Integration of distinct objects in visual working memory depends on strong objecthood cues even for different-dimension conjunctions. Cerebral Cortex, 26(5), 2093–2104. doi:https://doi.org/10.1093/cercor/bhv038
Bays, P. M., Catalao, R. F., & Husain, M. (2009). The precision of visual working memory is set by allocation of a shared resource. Journal of Vision, 9(10), 7–7. doi:https://doi.org/10.1167/9.10.7
Bertamini, M., & Croucher, C. J. (2003). The shape of holes. Cognition, 87(1), 33–54. doi:https://doi.org/10.1016/S0010-0277(02)00183-X
Bertamini, M., & Helmy, M. S. (2012). The shape of a hole and that of the surface-with-hole cannot be analyzed separately. Psychonomic Bulletin & Review, 19(4), 608–616. doi:https://doi.org/10.3758/s13423-012-0265-3
Brady, T. F., & Alvarez, G. A. (2011). Hierarchical encoding in visual working memory: Ensemble statistics bias memory for individual items. Psychological Science, 22(3), 384–392. doi:https://doi.org/10.1177/0956797610397956
Brady, T. F., Konkle, T., & Alvarez, G. A. (2011). A review of visual memory capacity: Beyond individual items and toward structured representations. Journal of Vision, 11(5):4, 1–34. doi:https://doi.org/10.1167/11.5.4
Cowan, N. (2001). The magical number 4 in short-term memory: A reconsideration of mental storage capacity. Behavioral & Brain Sciences, 24, 87–185. doi:https://doi.org/10.1017/s0140525x01003922
Delvenne, J. F., Braithwaite, J. J., Riddoch, M. J., & Humphreys, G. W. (2002). Capacity limits in visual short-term memory for local orientations. Current Psychology of Cognition, 21(6), 681–690.
Delvenne, J. F., & Bruyer, R. (2006). A configural effect in visual short-term memory for features from different parts of an object. The Quarterly Journal of Experimental Psychology, 59(9), 1567–1580. doi:https://doi.org/10.1080/17470210500256763
Duncan, J. (1984). Selective attention and the organization of visual information. Journal of Experimental Psychology: General, 113(4), 501–517. doi:https://doi.org/10.1037//0096-3445.113.4.501
Duncan, J. (1993). Similarity between concurrent visual discrimination: Dimensions and objects. Perception & Psychophysics, 54(4), 425–430. doi:https://doi.org/10.3758/BF03211764
Duncan, J., & Nimmo-Smith, I. (1996). Objects and attributes in divided attention: Surface and boundary systems. Perception & Psychophysics, 58(7), 1076–1084. doi:https://doi.org/10.3758/BF03206834
Faul, F., Erdfelder, E., Lang, A. G., & Buchner, A. (2007). G*Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behavior Research Methods, 39(2), 175–191. doi:https://doi.org/10.3758/bf03193146
Holm, S. (1979). A simple sequentially rejective multiple test procedure. Scandinavian Journal of Statistics, 6(2), 65–70.
Kanizsa, G., & Gerbino, W. (1976). Convexity and symmetry in figure–ground organization. In M. Henle (Ed.), Vision and artifact (pp. 25–32). New York, NY: Springer.
Koffka, K. (1935). Principles of Gestalt psychology. New York, NY: Harcourt Brace.
Lappin, J. S. (1967). Attention in the identification of stimuli in complex displays. Journal of Experimental Psychology, 75(3), 321–328. doi:https://doi.org/10.1037/h0025044
Luck, S. J., & Vogel, E. K. (1997). The capacity of visual working memory for features and conjunctions. Nature, 390, 279–281. doi:https://doi.org/10.1038/36846
Luria, R., & Vogel, E. K. (2014). Come together, right now: Dynamic overwriting of an object’s history through common fate. Journal of Cognitive Neuroscience, 26(8), 1819–1828. doi:https://doi.org/10.1162/jocn_a_00584
Magnussen, S., Greenlee, M. W., & Thomas, K. P. (1996). Parallel processing in visual short-term memory. Journal of Experimental Psychology: Human Perception and Performance, 22(1), 202–212. doi:https://doi.org/10.1037//0096-1523.22.1.202
Nelson, R., Thierman, J., & Palmer, S. E. (2009). Shape memory for intrinsic versus accidental holes. Attention, Perception, & Psychophysics, 71(1), 200–206. doi:https://doi.org/10.3758/APP.71.1.200
Olson, I. R., & Jiang, Y. (2002). Is visual short-term memory object based? Rejection of the “stong-object” hypothesis. Perception & Psychophysics, 64(7), 1055–1067. doi:https://doi.org/10.3758/BF03194756
Palmer, S., Davis, J., Nelson, R., & Rock, I. (2008). Figure–ground effects on shape memory for objects versus holes. Perception, 37(10), 1569–1586. doi:https://doi.org/10.1068/p5838
Rouder, J. N., Morey, R. D., Cowan, N., Zwilling, C. E., Morey, C. C., & Pratte, M. S. (2008). An assessment of fixed-capacity models of visual working memory. Proceedings of the National Academy of Sciences of the United States of America, 105, 5975–5979. doi:https://doi.org/10.1073/pnas.0711295105
Rouder, J. N., Morey, R. D., Morey, C. C., & Cowan, N. (2011). How to measure working memory capacity in the change detection paradigm. Psychonomic Bulletin & Review, 18(2), 324–330. doi:https://doi.org/10.3758/s13423-011-0055-3
Rubin, E. (1921). Visuell wahrgenommene figuren. Copenhagen, Denmark: Glydenalske boghandel.
Sewell, D. K., Lilburn, S. D., and Smith, P. L. (2014). An information capacity limitation of visual short-term memory. Journal of Experimental Psychology: Human Perception and Performance, 40(6), 2214–2242. doi:https://doi.org/10.1037/a0037744
Simons, D. J. (1996). In sight, out of mind: When object representations fail. Psychological Science, 7(5), 301–305. doi:https://doi.org/10.1111/j.1467-9280.1996.tb00378.x
Treisman, A. (1969). Strategies and models of selective attention. Psychological Review, 76(3), 282–299. doi:https://doi.org/10.1037/h0027242
Wheeler, M. E., & Treisman, A. M. (2002). Binding in short-term visual memory. Journal of Experimental Psychology: General, 131(1), 48–64. doi:https://doi.org/10.1037//0096-3445.131.1.48
Wilken, P., & Ma, W. J. (2004). A detection theory account of change detection. Journal of Vision, 4, 1120–1135. doi:https://doi.org/10.1167/4.12.11
Wing, A., & Allport, D. A. (1972). Multidimensional encoding of visual form. Perception & Psychophysics, 12(6), 474–476. doi:https://doi.org/10.3758/BF03210938
Xu, Y. (2002a). Encoding color and shape from different parts of an object in visual short-term memory. Perception & Psychophysics, 64(8), 1260–1280. doi:https://doi.org/10.3758/BF03194770
Xu, Y. (2002b). Limitions of object-based feature encoding in visual short-term memory. Journal of Experimental Psychology: Human Perception and Performance, 28(2), 458–468. doi:https://doi.org/10.1037//0096-1523.28.2.458
Xu, Y. (2006). Understanding the object benefit in visual short-term memory: The roles of feature proximity and connectedness. Perception & Psychophysics, 68(5), 815–828. doi:https://doi.org/10.3758/BF03193704
Zhang, J., & Mueller, S. T. (2005). A note on ROC analysis and non-parametric estimate of sensitivity. Psychometrika, 70(1), 203–212. doi:https://doi.org/10.1007/s11336-003-1119-8
Zhang, W., & Luck, S. J. (2008). Discrete fixed-resolution representations in visual working memory. Nature, 453, 233–236. doi:https://doi.org/10.1038/nature06860
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
McDunn, B.A., Brown, J.M. & Plummer, R.W. The influence of object structure on visual short-term memory for multipart objects. Atten Percept Psychophys 82, 1613–1631 (2020). https://doi.org/10.3758/s13414-019-01957-4
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-019-01957-4